요약
"End to End Learning for Self-Driving Cars"는 Nvidia에서 2016년에 발표한 연구 논문입니다. 이 논문은 자율 주행 자동차를 위한 딥러닝 접근 방법인 단일 신경망을 사용하여 전면 카메라의 이미지를 조향 명령으로 직접 매핑하는 "end-to-end" 시스템을 제안합니다. 이 접근 방식은 중간 처리 단계 없이 입력을 직접 출력으로 매핑하는 것이므로 "end-to-end" 시스템이라고 불립니다.
이 접근 방식에서 사용되는 네트워크 아키텍처는 합성곱 신경망(CNN)입니다. 이 네트워크는 전면 카메라 이미지 하나를 입력으로 받아 자동차의 조향값을 출력합니다. 이 네트워크의 학습 데이터는 조향각이 참값 레이블로 사용된 인간 운전 데이터에서 얻어집니다. 이 네트워크는 역전파(backpropagation)와 Adam 최적화 알고리즘을 사용하여 end-to-end로 학습됩니다.
이 접근 방식의 결과는 다양한 시나리오와 장애물이 있는 시험 트랙에서 평가됩니다. 논문은 end-to-end 시스템이 사고 없이 시험 트랙을 성공적으로 주행할 수 있었다고 합니다. 시스템은 또한 새로운 트랙과 시나리오에 대해서도 잘 일반화할 수 있었습니다.
Overview of the DAVE-2 System

DAVE-2의 학습 데이터 수집 시스템에 대한 단순화된 블록 다이어그램을 보여주고 있습니다. 학습 데이터 수집 차량의 앞유리 뒷쪽에는 세 개의 카메라가 장착되어 있습니다. 이 카메라에서 촬영한 비디오는 사람 운전자가 조향한 각도와 함께 타임 스탬프가 찍혀 캡처됩니다. 시스템이 차량 기하학에서 독립적이도록 하기 위해, 우리는 조향 명령을 미터 단위로 바꾸어 1/r로 표시합니다. 이 때, r은 미터 단위의 회전 반경을 의미합니다. 직진 시 회전 반경이 무한대가 되기 때문에, 우리는 직진 시에도 문제가 없도록 1/r을 사용합니다. 1/r은 좌회전(음수 값)에서 우회전(양수 값)으로 부드럽게 전환됩니다.
학습 데이터에는 비디오에서 샘플링된 단일 이미지와 해당하는 조향 명령(1/r)이 함께 포함됩니다. 그러나 사람 운전자 데이터만으로 학습을 진행하는 것은 충분하지 않습니다. 네트워크는 실수에서 복구하는 방법을 학습해야 합니다. 따라서 학습 데이터에는 차선 중심으로부터 다양한 거리와 도로 방향으로 회전한 자동차의 이미지가 추가됩니다.
카메라의 왼쪽 및 오른쪽에서 두 가지 특정한 오프센터 이동 이미지를 취득할 수 있습니다. 다른 이동 값과 모든 회전 값은 가장 가까운 카메라에서 이미지의 시점 변환을 통해 시뮬레이션됩니다. 정확한 시점 변환은 우리가 가지고 있지 않은 3D 장면 정보가 필요하지만, 지평선 아래의 모든 점이 평면 위에 있고, 지평선 위의 모든 점이 무한히 멀리 떨어져 있다고 가정하여 근사적으로 시점 변환을 수행합니다. 이는 평지 지형에서는 잘 작동하지만 건물, 나무, 기둥, 차량과 같은 지표면 위에 떠 있는 물체에 대해서는 왜곡이 발생할 수 있습니다. 그러나 이러한 왜곡은 네트워크 학습에 큰 문제가 되지 않습니다. 변환된 이미지의 조향 라벨은 차량을 원하는 위치와 방향으로 두 초 내에 조향할 수 있도록 조정됩니다.

학습 시스템의 블록 다이어그램은 Figure 2에 표시되어 있습니다. 이미지는 CNN에 공급되어 제안된 조향 명령이 계산됩니다. 제안된 명령은 해당 이미지에 대한 원하는 명령과 비교되며, CNN의 가중치는 CNN 출력을 원하는 출력에 가깝게 만드는 방식으로 조정됩니다. 가중치 조정은 Torch 7 기계 학습 패키지에서 구현된 역전파를 사용하여 수행됩니다.
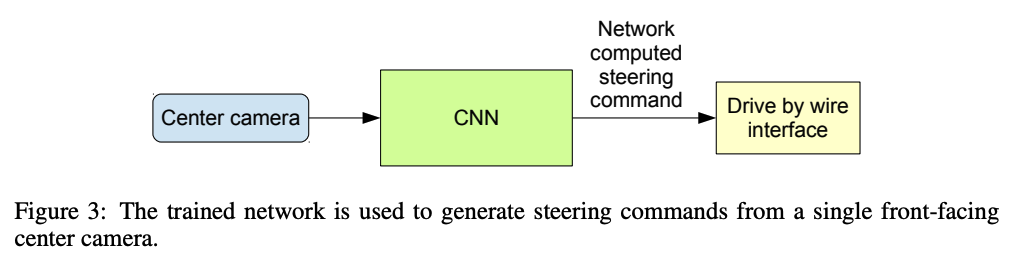
학습된 네트워크는 중앙 카메라의 비디오 이미지에서 조향을 생성할 수 있습니다. 이 구성은 Figure 3에 표시되어 있습니다.
Data Collection
데이터는 2016년식 린컨 MKZ 차량 또는 이와 유사한 위치에 카메라가 설치된 2013년식 포드 포커스를 사용하여 취득되었습니다. 이 시스템은 특정 차량 제조업체나 모델에 의존하지 않습니다. 운전자들은 완전한 주의를 유지하도록 권장되었지만, 그 외에는 보통대로 운전했습니다. 2016년 3월 28일 기준으로 총 72시간의 운전 데이터가 수집되었습니다.
Network Architecture

논문에서는 네트워크의 출력과 사람 운전자의 조향 명령 또는 중심에서 벗어난 이미지의 보정된 조향 명령 간의 평균 제곱 오차를 최소화하도록 네트워크의 가중치를 학습합니다.
네트워크 아키텍처는 Figure 4에 표시되어 있으며, 정규화 레이어, 5개의 컨볼루션 레이어 및 3개의 완전 연결 레이어를 포함하여 총 9개의 레이어로 구성됩니다. 입력 이미지는 YUV 평면으로 분할되어 네트워크로 전달됩니다. 네트워크의 첫 번째 레이어는 이미지 정규화를 수행합니다.
정규화기는 하드 코딩되어 있으며 학습 과정에서 조정되지 않습니다. 네트워크에서 정규화를 수행하면 정규화 방식을 네트워크 아키텍처에 따라 변경하고 GPU 처리를 통해 가속화할 수 있습니다. 컨볼루션 레이어는 특징 추출을 수행하도록 설계되었으며, 레이어 구성을 다양화한 일련의 실험을 통해 경험적으로 선택되었습니다.
첫 세 개의 컨볼루션 레이어에서는 2×2 스트라이드와 5×5 커널을 사용하여 스트라이드 컨볼루션을 사용하고, 마지막 두 컨볼루션 레이어에서는 3×3 커널 크기의 스트라이드 없는 컨볼루션을 사용합니다. 다섯 개의 컨볼루션 레이어 다음에는 세 개의 완전 연결 레이어가 따라오며, 출력 제어 값은 반전된 회전 반경입니다.
완전 연결 레이어는 조향기로 작동하도록 설계되었지만, 엔드-투-엔드로 시스템을 학습함으로써 네트워크의 어떤 부분이 기능 추출기로 주로 작동하고 어떤 부분이 조종기로 작동하는지 깔끔하게 구분할 수 없다는 점이 특징입니다.
Training Details
운전자가 차선을 유지한 데이터만 선택하고 나머지 데이터는 삭제합니다. 그런 다음 비디오를 10 FPS로 샘플링합니다. 더 높은 샘플링 속도는 매우 유사한 이미지를 포함하여 유용한 정보를 제공하지 못할 수 있으므로 제외합니다. 직선 주행으로 인한 편향을 제거하기 위해 굽은 도로의 프레임 비율이 높은 학습 데이터를 사용합니다.
Simulation
CNN의 성능을 평가하기 전에, 시뮬레이션에서 네트워크 성능을 먼저 평가합니다. 시뮬레이터는 인간 운전자가 운전한 차량의 전방 카메라에서 녹화된 비디오를 사용하여, CNN이 차량을 조종하는 경우의 시각을 근사적으로 생성합니다. 시뮬레이터는 녹화된 테스트 비디오와 함께 동기화된 조향 명령을 사용하여 가상의 차량의 위치와 방향을 업데이트합니다.
각 프레임의 가운데에서 벗어난 정도(초록색 라인)와 운행 거리 및 자동차의 회전 방향도 기록됩니다. 가운데에서 벗어난 정도가 1미터를 초과하면 "가상의 인간 개입(virtual human intervention)"이 트리거되어 가상 차량 위치 및 방향이 원본 테스트 비디오의 해당 프레임의 "ground truth"와 일치하도록 재설정됩니다. 이러한 가상 테스트에서의 모델 성능은 모바일 GPU 기반 드라이빙 스테이션(Mobileye Drive)을 통해 일부 개발자들에게 피드백을 받았습니다. 가상 테스트가 통과된 후, 테스트 세트의 차량에서 실제 도로 테스트를 진행합니다.
그 결과, 98% 이상의 시간을 차선에서 유지할 수 있었고, 1,000 마일 이상을 주행하는 동안 인간 개입이 필요한 경우는 0.8%에 불과했습니다. 이번 프로젝트의 핵심은 데이터로부터 컴퓨터 비전을 통해 차량 주행을 배우는 엔드 투 엔드(end-to-end) 학습 방법을 개발하는 데에 있었습니다.
Evaluation
7.1 시뮬레이션 테스트

실제 주행에서의 개입이 발생하는 빈도를 모사하여 자율주행 능력을 추정합니다. 인간 운전자의 개입이 필요한 경우를 1회로 간주하여, 일정 시간당 개입 횟수를 측정하여 자율주행 능력을 평가합니다.
7.2 도로 주행 테스트
시뮬레이션에서 자율주행 능력이 검증되면 실제 도로 주행 테스트를 진행합니다. 도로 주행 테스트에서는 인간 운전자의 차선 변경 및 도로 변경을 제외한 시간 동안 자율주행한 비율을 측정하여 성능을 평가합니다.
7.3 CNN 내부 상태 시각화
본문에서는 CNN 내부 상태의 시각화에 대한 결과도 제시하고 있습니다. 비포장도로나 숲과 같이 주행에 미치는 영향이 다른 경우에 대해 CNN의 내부 상태를 시각화하여, 네트워크가 도로의 특징을 감지하고 이를 통해 주행을 제어할 수 있도록 학습되었음을 보여줍니다.
Conclusions
연구진은 CNN이 도로 및 차선을 따라가는 작업을 수동적으로 분해 없이 배울 수 있다는 것을 입증했다. 수십 시간 미만의 적은 양의 데이터로, 세 가지 다른 기상 조건에서, 고속도로, 지역 도로 및 주택가 도로에서 차량을 운전할 수 있게 훈련시켰다. 이 시스템은 제어를 위해 운전 커맨드(조향 정보) 만을 훈련 신호로 사용하면서도 의미있는 도로 특징을 배울 수 있다는 것을 입증했다. 이를 통해 도로의 윤곽선과 같은 유용한 특징을 학습할 수 있다.
'자율주행' 카테고리의 다른 글
| [자율주행 논문] Scaling Self-Supervised End-to-End Driving with Multi-View Attention Learning (0) | 2023.03.24 |
|---|---|
| [자율주행 차선관련 논문] End-to-end Lane Shape Prediction with Transformers (0) | 2023.03.24 |
| [코딩] Python을 이용한 고전적 방식의 차선인식1_(코드) (0) | 2023.01.01 |
| [코딩] Python을 이용한 고전적 방식의 차선인식1_색상추출 (1) | 2023.01.01 |
| 간단하게 알아보는 자율주행차 인지 센서들 (1) | 2022.12.14 |



댓글