Abstract
이 논문은 자율주행차에 중요한 다양한 환경에서 교통선을 감지하는 새로운 방법에 관한 것입니다. 이 방법을 PINet(Point Instance Network)이라고 하며, 키 포인트를 추정하고 인스턴스 분할이라는 기술을 사용하여 작동합니다. PINet은 함께 훈련된 multiple stacked hourglass 네트워크를 사용합니다. 이를 통해 시스템은 사용 중인 환경에서 사용 가능한 컴퓨팅 성능에 따라 적절한 모델 크기를 선택할 수 있습니다. 이 방법은 키 포인트 클러스터링(Clustering key points) 문제를 인스턴스 분할 문제(instance segmentation issue)로 다루기 때문에 트래픽 라인 수에 관계없이 훈련될 수 있습니다. PINet은 차선 감지에 대해 잘 알려진 두 개의 데이터 세트인 TuSimple 및 Culane에서 정확도 및 false positives 측면에서 우수한 성능을 발휘합니다.
1. INTRODUCTION
차선을 인식하는 방법은 교통선 감지 및 도로 지역 분할을 포함하여 다양합니다. 이 논문에서는 트래픽 라인 탐지에 중점을 둡니다.

기존의 트래픽 라인 감지 방법은 색상이나 가장자리와 같은 간단한 기능을 사용하고 Hough 변환 또는 Kalman 필터와 같은 기술을 사용하여 이를 결합합니다. 이러한 방법은 다양한 환경에 적응할 수 있지만, 그 성능은 조명(lighting) 및 occlusion과 같은 요소에 따라 달라집니다. CNN(Convolutional Neural Networks)과 같은 딥 러닝 방법은 복잡한 장면에서 더 나은 성능을 보여줍니다. 의미론적 분할은 종종 트래픽 라인 감지에 사용되지만, 이러한 방법은 픽셀 레벨 레이블링을 필요로 하며 고정된 수의 트래픽 라인만 처리할 수 있습니다. 이러한 한계를 극복하기 위해 저자는 multiple stacked hourglass 네트워크를 사용하여 트래픽 라인의 주요 지점을 예측하는 방법을 제안합니다.
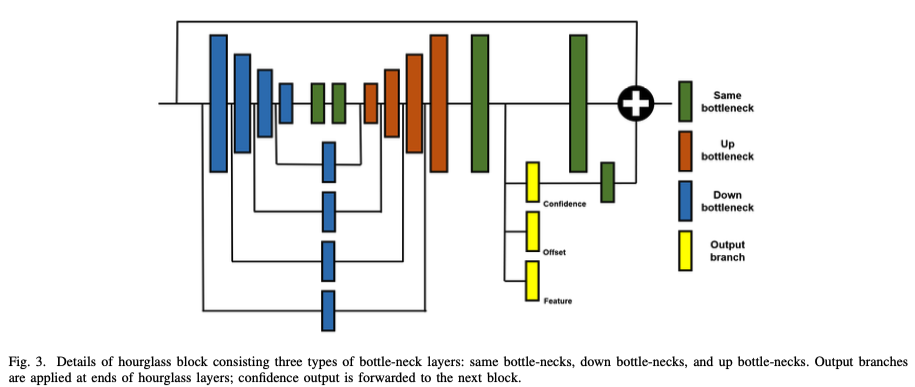
multiple stacked hourglass 네트워크는 다양한 규모로 정보를 추출할 수 있으며 다양한 컴퓨팅 전력 환경에 적응할 수 있습니다. 구조의 일부를 클리핑(clipping)하여 매개변수 크기가 다른 모형을 동시에 만들 수 있습니다. 이 방법은 포인트 클라우드 인스턴스 분할에서 영감을 얻은 접근 방식을 사용하여 주요 포인트를 개별 인스턴스로 구분합니다. 또한 트래픽 라인을 잘못 식별하면 자율 주행 차량에 위험한 상황이 발생할 수 있기 때문에 false positives을 줄이는 것의 중요성을 강조합니다.
2. RELATED WORK
A. Traffic Line Detection
기존 방법은 수작업 기능을 사용하지만 복잡한 시나리오에서는 한계가 있습니다. 딥러닝은 컴퓨터 비전에서 인기를 끌었으며, 의미론적 세분화가 주요 주제입니다. 의미론적 분할 및 생성 방법(Semantic segmentation and generative methods)은 입력 이미지에서 픽셀을 분류할 수 있으며 복잡한 선 모양을 표현하는 데 적합합니다. 이러한 메소드는 다중 클래스 접근 방식을 사용하여 서로 다른 인스턴스를 구별할 수 있지만 고정된 수의 인스턴스만 처리할 수 있습니다. 이러한 한계를 극복하기 위해 인스턴스 분할 접근 방식(instance segmentation approaches)이 제안되었습니다.
의미론적 분할 방법은 복잡한 모양을 예측할 수 있지만 픽셀 수준의 레이블링된 데이터와 사후 처리가 필요합니다. 직접 메서드는 라인에서 정확한 점을 생성하지만 불필요한 출력 값도 많이 생성합니다. 트래픽 라인을 인식하는 데 모든 픽셀이 필요한 것은 아니며 몇 가지 주요 지점에서 정확한 라인을 예측할 수 있기 때문에 두 가지 접근 방식 모두 단점이 있습니다. 해당 논문은 불필요한 예측이 적은 트래픽 라인을 인식하고 다른 환경에 적응할 수 있는 보다 효율적인 트래픽 라인 감지 방법의 필요성을 강조합니다.
B. Key Points Estimation
입력 이미지에서 키 포인트라고 하는 중요한 포인트를 예측하는 데 사용되는 키 포인트 추정 기법에 대해 설명합니다. 인간 자세 추정은 이 분야의 주요 연구 주제입니다.
여러 개의 hourglass modules로 구성된 Stacked hourglass networks는 다양한 규모의 정보를 더 깊은 계층으로 전송할 수 있습니다. 이렇게 하면 네트워크가 글로벌 피쳐(global features)과 로컬 피쳐(local features)를 모두 캡처할 수 있습니다. 따라서 hourglass networks는 객체 탐지 작업에서 객체의 중심 또는 모서리를 탐지하는 데 종종 사용됩니다.
네트워크 아키텍처 및 손실 기능 외에도 키포인트 추정을 개선하기 위한 개선 방법이 개발되었습니다. 일부 방법에는 multi-stage methods에 적용할 수 있는 기능 집합에서 supervision과 기존 모델의 결과를 개선하는 개선 네트워크가 포함됩니다. 이러한 개선 방법은 논문의 제안된 프레임워크에서 사용되지 않지만 성능을 향상시키기 위해 잠재적으로 적용될 수 있습니다.
3. METHOD
포인트 인스턴스 네트워크(PINET, Point Instance Network)라는 신경망을 사용하여 차선을 감지하는 방법을 설명합니다. 네트워크는 여러 개의 hourglass modules로 구성되어 있으며 차선에서 포인트를 생성하고 이러한 포인트를 개별 인스턴스로 구분하도록 설계되었습니다.
PINet에는 confidence, offset및 embedding의 세 가지 출력 분기가 있습니다. confidence, offset 분기는 YOLO에서 영감을 얻은 손실 함수를 사용하여 트래픽 라인의 정확한 지점을 예측합니다. embedding 분기는 예측된 각 점에 대한 embedding 기능을 생성한 다음 클러스터링 프로세스에서 개별 인스턴스를 구별하는 데 사용됩니다. embedding 분기에 대한 손실 함수는 유사성 그룹 제안 네트워크(SPGN, Similarity Group Proposal Network)라는 인스턴스 분할 방법에서 영감을 받았습니다.
A. Architecture
프레임워크는 512x256 RGB 이미지를 입력으로 사용하며, 크기 조정 네트워크에 의해 크기가 64x32로 조정됩니다. 크기가 조정된 이미지는 동시에 훈련된 여러 hourglass modules로 구성된 예측 네트워크에 공급됩니다. 각 hourglass modules에는 트래픽 라인의 정확한 지점과 인스턴스 분할을 위한 embedding 기능을 예측하기 위한 인코더(encoder), 디코더(decoder) 및 세 개의 출력 분기(confidence, offset 및 embedding)가 있습니다.
B. Loss Function
confidence 손실: 네트워크가 트래픽 라인의 주요 지점이 출력 그리드의 각 셀에 있는지 여부를 얼마나 잘 예측하는지 측정합니다.
offset 손실: 네트워크가 각 출력 셀에 대한 키 포인트의 정확한 위치를 얼마나 정확하게 예측하는지 측정합니다.
embedding Feature 손실: 네트워크가 동일한 인스턴스에 속한 셀의 임베딩 기능을 더 가깝게 만들고 다른 인스턴스에 속한 셀의 임베딩 기능을 더 멀리 떨어지게 합니다.
Distillation 손실: 지식 증류를 사용하여 보다 가벼운 네트워크의 성능을 향상시켜 보다 심층적인 네트워크의 성능을 모방할 수 있습니다.
총 손실은 이 네 가지 손실 조건의 가중 합계이며, 네트워크는 종단 간(end-to-end) 절차를 사용하여 훈련됩니다.
C. Implementation Detail
입력 이미지는 512x256으로 크기가 조정되고 0-255의 RGB 값에서 0-1로 정규화된 후 훈련 및 테스트를 위해 네트워크에 공급됩니다. 데이터 세트에서 희소 주석(sparse annotations)을 처리하기 위해 선형 회귀를 사용하여 x축의 10픽셀마다 추가 주석이 만들어집니다.

입력 영상에는 쉐이딩, 노이즈 추가, 플립, 변환, 회전 및 강도 변경(shadowing, adding noise, flipping, translation, rotation and ntensity changing)과 같은 다양한 데이터 확대 기술이 적용됩니다.
데이터 세트의 불균형을 해결하기 위해 훈련 중 손실 값이 낮은 하드 데이터를 샘플링하고 선택 비율을 높입니다. 이 개념은 하드 네거티브 마이닝(hard negative mining.)과 유사합니다.
네트워크는 PyTorch를 사용하여 하나의 GPU(GTX 2080ti 11GB)에서 교육 및 테스트됩니다. 각 배치에는 6개의 이미지가 포함되어 있으며 임계값 및 계수와 같은 하이퍼 파라미터가 실험적으로 결정됩니다.
PINet은 트래픽 라인에서 주요 지점의 정확한 위치를 예측하고, 보다 부드러운 곡선을 얻기 위해 스플라인 곡선 피팅 방법을 적용합니다.
4. EXPERIMENTS
PINet은 TuSimple 및 CULane 데이터 세트 모두에서 교육을 받았으며, 장애물이 적은 고속도로 환경으로만 구성되어 있기 때문에 TuSimple이 비교적 단순합니다.
TuSimple 데이터 세트에는 3,626개의 교육 세트와 2,782개의 테스트 세트가 있습니다. 주요 평가 메트릭은 정확도이며, 정확도는 정확하게 예측된 평균 점 수를 기반으로 계산됩니다. 또한 거짓 음성(FN) 및 거짓 양성(FP) 속도를 제공합니다.
CULane 데이터 세트에는 88,880개의 교육 이미지와 34,680개의 테스트 이미지가 있습니다. 도시 및 야간 환경과 같은 다양한 도로 유형을 포함합니다. CULane에 대한 공식 평가 메트릭은 F1-measure이며, 이는 각 트래픽 라인의 폭이 30픽셀이라고 가정할 때 예측된 트래픽 라인과 실측값 사이의 교차점-over-Union(IoU)을 사용하여 계산됩니다.
Result

TuSimple: PINet은 정확도와 false positive 및 합리적인 false negative rate 측면에서 높은 성능을 보여줍니다. 파라미터 수와 초당 프레임 수(fps)는 hourglass modules 수를 기준으로 표시됩니다. PINet은 모든 hourglass 네트워크에서 25fps로 실행되고 hourglass 네트워크 하나에서만 40fps로 실행될 수 있습니다. 잘라낸 짧은 네트워크의 성능은 가장 깊은 네트워크와 약간 다릅니다.
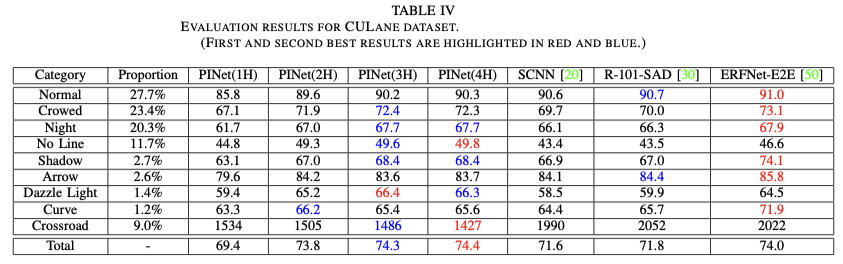
CULane: PINet은 특히 낮은 false positive rate로 CULane 데이터 세트에서 우수한 성능을 발휘하여 안전 성능을 보장합니다. 클리핑된 네트워크 2H 및 3H는 전체 네트워크와 유사한 성능을 보여줍니다. PINet은 조명이 밝은 조건에서는 성능이 우수하지만 local occlusions이나 불분명한 트래픽 라인에 의해 부정적인 영향을 받을 수 있습니다.
Ablation Study: knowledge distillation method의 목적은 잘라낸 짧은 네트워크(clipped short network)와 가장 깊은 네트워크 사이의 간격을 줄이는 것입니다. 결과는 distillation 방법이 적용될 때 전체 네트워크와 클리핑된 짧은 네트워크 사이의 평균 성능 차이가 더 작다는 것을 보여주는데, 이는 distillation 방법이 클리핑된 짧은(clipped short) 네트워크가 teacher 네트워크를 잘 모방하는 데 도움이 된다는 것을 의미합니다.
5. CONCLUSION
본 연구에서는 포인트 추정과 포인트 인스턴스 분할 방법을 결합한 PINet이라는 새로운 차선 감지 방법을 제안합니다. PINet은 실시간으로 작동하며 추가 교육 없이 시스템의 컴퓨팅 성능에 따라 조정할 수 있습니다. 높은 성능과 낮은 오검출률을 제공하며, 잘못된 차선 발생을 줄여 자율주행차의 안전성을 보장합니다. PINet은 까다로운 조명 조건에서는 성능이 더 뛰어나지만 local occlusions이나 불분명한 트래픽 라인의 경우에는 한계가 있습니다. nowledge distillation 방법은 클리핑된 짧은 네트워크(clipped short network)의 성능을 향상시켜 전체 네트워크의 성능에 더 가깝게 합니다.
c.f.
핵심 포인트를 인스턴스 분할 문제로 클러스터링하는 것?
연구에서 제안된 차선 감지 방법의 맥락에서, 핵심 포인트를 인스턴스 분할 문제로 클러스터링하는 것은 각 그룹이 단일하고 구별되는 차선 라인을 나타내도록 감지된 핵심 포인트를 그룹화하는 프로세스를 말합니다.
Clustering key points: 이는 일련의 키포인트(관심 대상 개체의 특정 위치)를 근접성 또는 유사성에 따라 별도의 클러스터로 그룹화하거나 구성하는 프로세스를 말합니다. 차선 감지의 맥락에서 키 포인트는 차선 라인의 위치를 나타냅니다. 목표는 동일한 차선 선에 속하는 주요 점을 클러스터에 함께 그룹화하여 각 클러스터가 하나의 개별 차선 선을 나타내도록 하는 것입니다.
Instance segmentation issue: 이미지 내에서 관심 있는 개체를 탐지하고 분리하는 동시에 각 개별 개체 인스턴스를 분류하는 것과 관련된 광범위한 컴퓨터 비전 문제입니다. 객체뿐만 아니라 객체의 경계를 식별하고 동일한 클래스의 인스턴스를 구별해야 하므로 키포인트를 클러스터링하는 것을 넘어섭니다.
이 논문에서 관심 대상은 차선 선이며 키 포인트는 해당 차선 선의 특정 위치를 나타냅니다. 각 클러스터가 단일 차선 라인에 해당하는 개별 클러스터로 이러한 주요 지점을 구성하는 것입니다. 이 인스턴스 분할 문제를 해결함으로써 제안된 방법은 서로 가깝거나 복잡한 기하학적 구조를 가지고 있는 경우에도 이미지에서 서로 다른 차선 라인을 정확하게 감지하고 구별할 수 있습니다.
Local occlusions?
전방에 다른 물체가 있어 물체나 장면의 일부가 가려지거나 보이지 않는 상황을 말합니다. 컴퓨터 비전 및 차선 감지의 맥락에서, 차량, 보행자 또는 다른 물체가 차선 라인의 일부 보기를 차단할 때 국부적 폐색(Local occlusions)이 발생할 수 있습니다. 국부적 폐색은 막힌 부분이 이미지에서 보이지 않을 수 있기 때문에 차선 감지 알고리즘이 차선 라인의 전체 범위를 정확하게 식별하고 추적하는 것을 더 어렵게 만들 수 있습니다. 이는 잠재적으로 차선 라인의 위치를 인식하고 예측하는 알고리즘의 성능과 정확도에 영향을 미칠 수 있습니다.
함께 보면 좋은 글



댓글